XSS&反射型XSS
编码
URL编码
ASCII 码 -> 16进制 -> %+
定义与用途
URL 编码是对 URL 中非安全字符(如空格、特殊符号)的转换规则,目的是确保 URL 能被正确传输和解析。浏览器会自动对 URL 中的特殊字符编码,攻击者可利用其绕过服务器对特定字符(如<、>、")的过滤。
编码规则
以
%加两位十六进制数表示字符(ASCII 码)。安全字符(如字母、数字、
-、_、.、~)不编码。特殊字符编码示例:
字符 含义 URL 编码 空格 %20<小于号 %3C>大于号 %3E"双引号 %22'单引号 %27(左括号 %28)右括号 %29=等号 %3D
应用场景(XSS 绕过)
当服务器过滤<或>时,可用 URL 编码绕过。例如:
原 Payload:<script>alert(1)</script>
编码后:%3Cscript%3Ealert(1)%3C/script%3E
若服务器只解码一次,可能直接执行编码后的代码。
HTML实体编码
定义与用途
HTML 实体编码用于在 HTML 中表示特殊字符(如<、&),避免浏览器将其解析为 HTML 标签或语法。攻击者可利用其在 HTML 上下文(如标签属性、文本内容)中注入恶意代码,绕过对特殊字符的过滤。
编码规则
有三种形式:
&name;(命名实体)、&#number;(十进制)、&#xnumber;(十六进制)。常用字符编码示例:
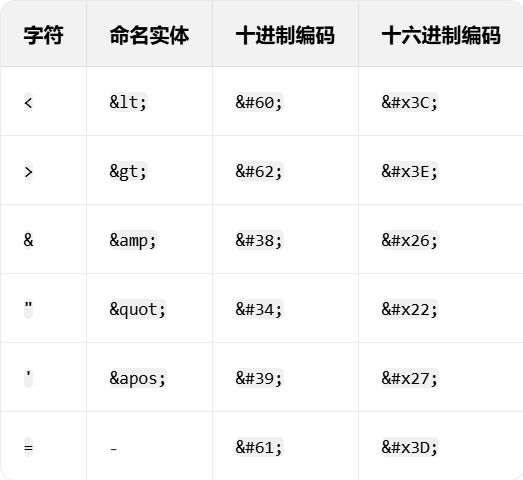
应用场景(XSS 绕过)
- HTML 标签内文本:若直接输出用户输入,编码后的字符会被解析为原字符。例如:
注入<script>alert(1)</script>,浏览器解析后为<script>alert(1)</script>,触发 XSS。 - 标签属性中:在
href、onclick等属性中,十进制 / 十六进制编码可能被解析。例如:<a href="javascript:alert(1)">点击</a>(alert(1)的十进制编码),点击后执行弹窗。
Unicode编码
ASCII 码 -> 16进制 -> \u00+
定义与用途
Unicode 编码是国际标准字符集,为每个字符分配唯一数字编码(码点)。在 Web 中,可通过\u前缀表示 Unicode 转义序列(适用于 JavaScript),或&#x前缀(适用于 HTML,同 HTML 实体十六进制编码)。攻击者可利用其绕过对特定字符(如字母、符号)的过滤。
编码规则
- JavaScript 中:以
\u加 4 位十六进制数表示,例如a的 Unicode 编码为\u0061,(为\u0028。 - HTML 中:同 HTML 实体的十六进制编码(
&#x+ 码点),例如alert可编码为alert。
应用场景(XSS 绕过)
- JavaScript 上下文:当服务器过滤
alert等关键词时,可用 Unicode 编码替换字母。例如:
原代码:alert(1)
编码后:\u0061\u006C\u0065\u0072\u0074(\u0031)
若浏览器在 JS 解析时自动解码,则会执行弹窗。 - 混合编码绕过:结合 URL 编码和 Unicode 编码,例如将
\u003C(<)再进行 URL 编码为%5Cu003C,绕过多层过滤。
深入理解
浏览器解析机制和XSS向量编码
解析流程:html解析 -> url解析 -> js解析
HTML 解析:搭建页面骨架(DOM 树)
HTML 解析器的工作是把 HTML 文本转换成 DOM 树(类似 “家谱”,每个标签是一个节点)。它逐字逐句读文本,遇到特殊符号就切换状态,比如看到<就知道 “要开始解析标签了”。
解析器特性:
HTML 解析器是基于状态机的逐字符解析器,具有强容错性(对不规范语法自动修正,如未闭合标签、错误嵌套等)。例如:
1 | <div><p>test</div> <!-- 浏览器会自动补全</p>,修正为<div><p>test</p></div> --> |
这种容错性可能导致攻击者构造的 “畸形” 代码被解析为有效标签。、
状态机:
- 在解析过程中,任何时候它只要遇到一个’<’符号(后面没有跟’/‘符号)就会进入“标签开始状态(Tag open state)”
- 然后转变到“标签名状态(Tag name state)”,“前属性名状态(before attribute name state)”……
- 最后进入“数据状态(Data state)”并释放当前标签的token
- 当解析器处于“数据状态(Data state)”时,它会继续解析,每当发现一个完整的标签,就会释放出一个token。
容纳html实体编码的三种情况
- 数据状态中的字符引用
- RCDATE状态中的字符引用
- 属性值状态中的字符引用
在这些状态中,html字符实体会从“&#…”形式解码,对应的字符会被放入数据缓冲区,但是解析器在解析这个字符引用后不会转换到“标签开始状态”。正因为如此,就不会建立新标签。因此,我们能够利用字符实体编码这个行为来转义用户输入的数据从而确保用户输入的数据只能被解析成“数据”。
html五类元素
空元素,如area,br,base等,自闭和标签,不能容纳任何内容
原始文本元素,script 和 style ,直接展示其中的文本内容,不会尝试解析为标签
RCDATA,textarea 和 title , 只解析自己的闭合标签 /textarea 和 /title ,其余标签一概不认
在浏览器解析RCDATA元素的过程中,解析器会进入“RCDATA状态”。在这个状态中,如果遇到“<”字符,它会转换到“RCDATA小于号状态”。如果“<”字符后没有紧跟着“/”和对应的标签名,解析器会转换回“RCDATA状态”。
外部元素,如 svg ,可以容纳文本,字符引用,CDATA段,其他元素和注释
基本元素,除以上外所有元素,可以容纳文本,字符引用,其他元素和注释
URL 解析:定位资源的 “导航系统”
当 HTML 解析器遇到带 URL 的属性(如href、src),或 JavaScript 里用到location.href时,会调用URL 解析器处理。它的作用是把 URL 字符串拆成可理解的部分(比如协议、域名、路径),并处理编码,确保资源能被正确找到。
- URL资源类型必须是ASCII字母(U+0041-U+005A || U+0061-U+007A),不然就会进入“无类型”状态。例如,你不能对协议类型进行任何的编码操作,不然URL解析器会认为它无类型。
- URL编码过程使用UTF-8编码类型来编码每一个字符。如果你尝试着将URL链接做了其他编码类型的编码,URL解析器就可能不会正确识别。
JavaScript 解析:严格区分大小写,不能对符号编码
当 HTML 解析器遇到<script>标签或onclick这类事件属性时,会暂停工作,让 JavaScript 解析器接手。JS 解析器的任务是把代码字符串转换成可执行的指令。
- 控制字符:当用Unicode转义序列来表示一个控制字符时,例如单引号、双引号、圆括号等等,它们将不会被解释成控制字符,而仅仅被解码并解析为标识符名称或者字符串常量。
- 标识符名称中:当Unicode转义序列出现在标识符名称中时,它会被解码并解释为标识符名称的一部分
- js 解码数字后,会将数字当作字符串,而js中字符串必须用引号包裹
多解析器协同
当 JS 用innerHTML或document.write()生成新的 HTML 时,浏览器会重新调用 HTML 解析器处理这些内容(相当于 “二次解析”)。比如:
1 | document.write('<img src="x" onerror="alert(1)">'); |
JS 执行后生成了<img>标签,HTML 解析器会重新解析这个标签,触发onerror事件,最终执行alert(1)。